LR一般用来解决二分类问题,表达能力比较弱,可以简单的这样理解:LR是一个拟合因和果的算法,它认为任何结果y必定和一系列因x存在某些关系w。虽然比较朴实,但LR真的是一个万金油的算法,我们在很多工作中(CTR预估、游戏推荐、系统运维…)都用到了。因为LR:
- 简单、有效(数据量大到一定程度,这些模型的效果其实差别并不大), 可解释性好。
- 简单易部署,分布式训练算法比较成熟(在大数据场景下,训练速度快、消耗资源少),适合online learning。
- 稳定。
基本假设
线性回归假设数据服从高斯分布,所以用一个平面(线性决策边界)可以把数据分开。但现实中数据并不都是完美的高斯分布,所以逻辑回归假设数据服从伯努利分布,通过逻辑函数(Sigmoid)作一层隐射,用一个曲面(非线性决策边界)去分开数据。逻辑回归的假设函数形式如下:
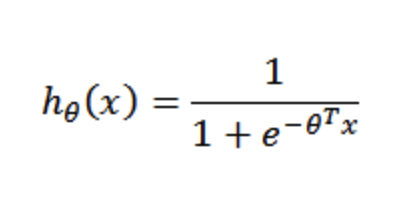
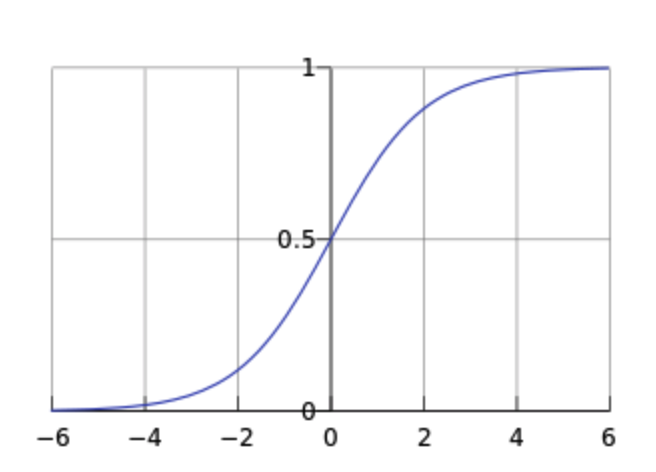
其实这就是个sigmoid函数,见下图:
特征工程
因为LR比较朴实,表达能力较弱,所以做LR百分之80的工作其实是在做特征工程。毕竟只有找对了因,才能到达正确的果。
-
归一化: 归一化可以提高收敛速度,提高收敛的精度。具体参考为什么一些机器学习模型需要对数据进行归一化?。
-
离散化: 为什么要离散化,这里直接粘贴下网上找的:

-
组合特征: 组合特征和特征离散化其实意义很类似,都是希望在更高阶的空间里找到划分曲面。通过组合低阶特征,提升模型的非线性表达。
-
特征相关性 训练的过程当中最好将高度相关的特征去掉:
1) 去掉高度相关的特征会让模型的可解释性更好。
2) 如果模型当中有很多特征高度相关的话,就算损失函数本身收敛了,但实际上参数是没有收敛的,这样会拉低训练的速度。
3) 减少特征,自然会减少训练的时间。 -
GBDT: 在处理特征离散化和组合特征的过程中有些问题需要人工经验来确定,比如
1) 连续变量切分点如何选取?
2) 离散化为多少份合理?
3) 选择哪些特征交叉?多少阶交叉,二阶,三阶或更多?
gbdt对于数据离散,会根据信息增益,客观的选取切分点和份数。而gbdt的叶子节点,其实就是特征组合的结果。 -
特征评估: 评估特征好坏的方法有ABtest,卡方检验,单特征AUC等。比较保险点办法就是在ab test系统去测试新加某个维度带来的ctr变化。
损失函数
损失函数衡量的是实际值和预估值的差异。所以有很多函数可以来衡量这个距离:
 LR一般用对数损失:cost(hθ(x),y)=∑i=1m−yilog(hθ(x))−(1−yi)log(1−hθ(x))。原因参考这里。
LR一般用对数损失:cost(hθ(x),y)=∑i=1m−yilog(hθ(x))−(1−yi)log(1−hθ(x))。原因参考这里。
模型训练
-
样本均衡: LR对样本均衡比较敏感,所以尽量还是保证正负样本1:1的比例。如果样本不均衡,可以参考这里的方法。
-
模型训练: lr的训练过程其实是一个无约束问题的求解过程:求最小的θ,使得损失函数最小。常见的最优化方法有梯度下降法、牛顿法和拟牛顿法、共轭梯度法等。GD -> BGD -> SGD。
-
模型评估: // TODO
-
过拟合&欠拟合: // TODO
实现框架
SGD的分布式实现一直是业界比较关注的问题, 而问题的本质就是怎么减少进程间订单通讯开销、提高高维数据下的可扩展性。
-
tree all reduce: spark的实现方式,两阶段树分裂算法。每次迭代会把所有参数广播到各个节点,然后分两阶段reduce到driver汇总更新。不管是速度,还是可扩展性,这种实现方式都比较差,所以spark的MLLib一直被人诟病。
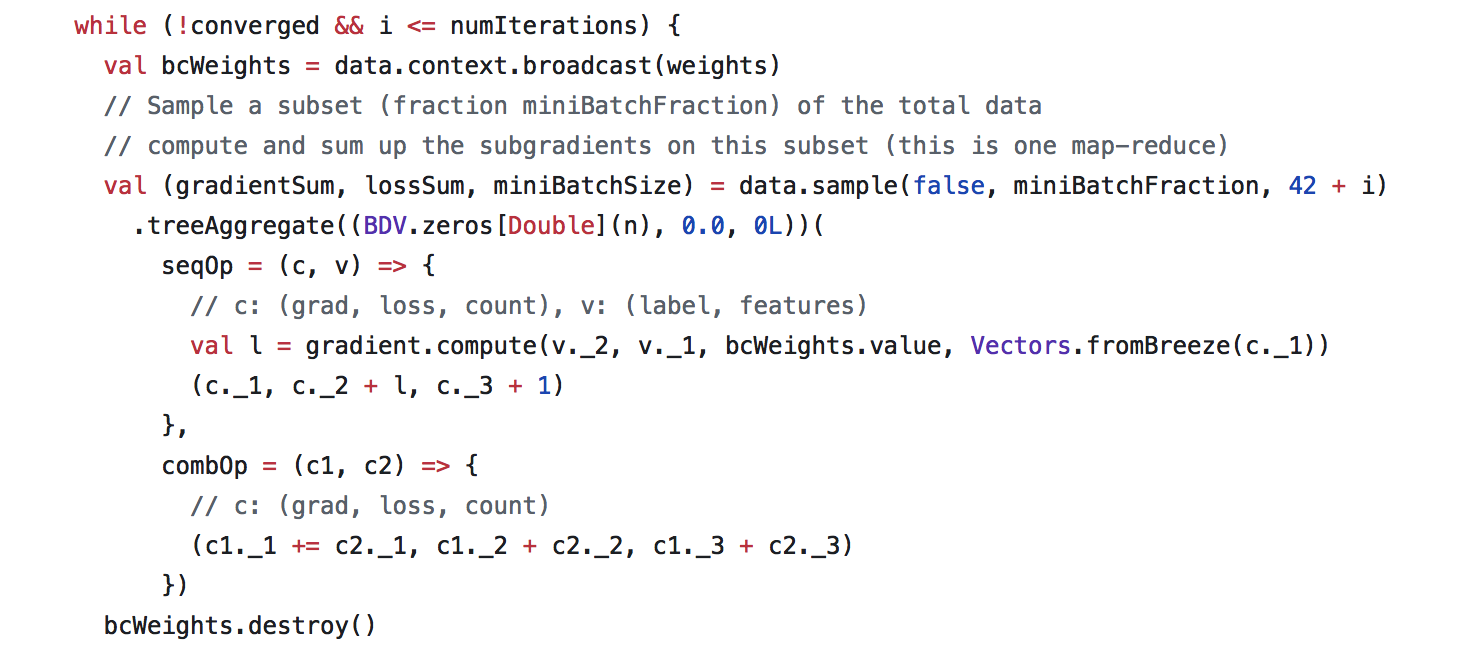
-
ps: 参数服务器,将参数和数据都分布式存储、训练、更新。比如tencent angel就是这种实现方式。
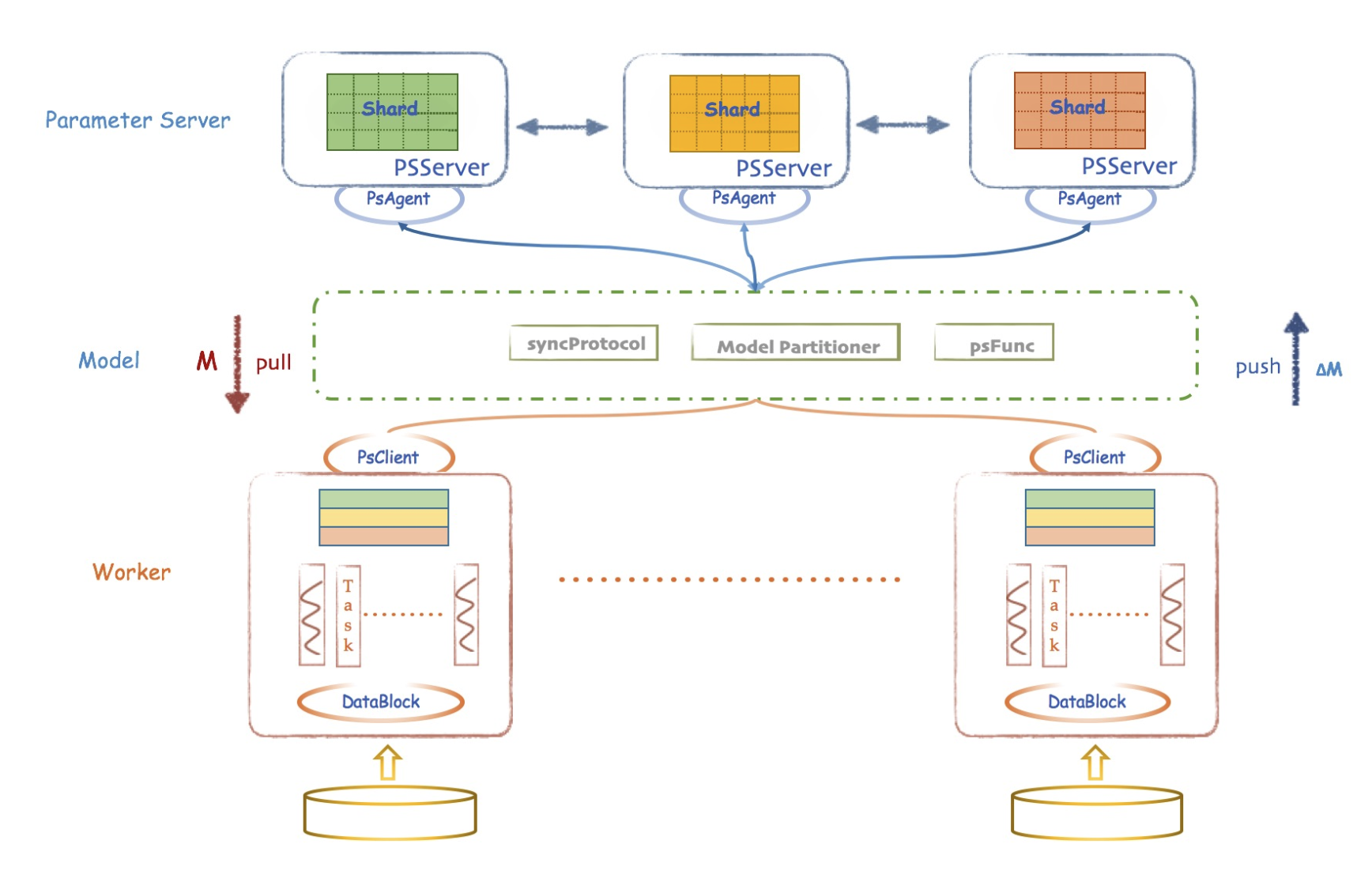
-
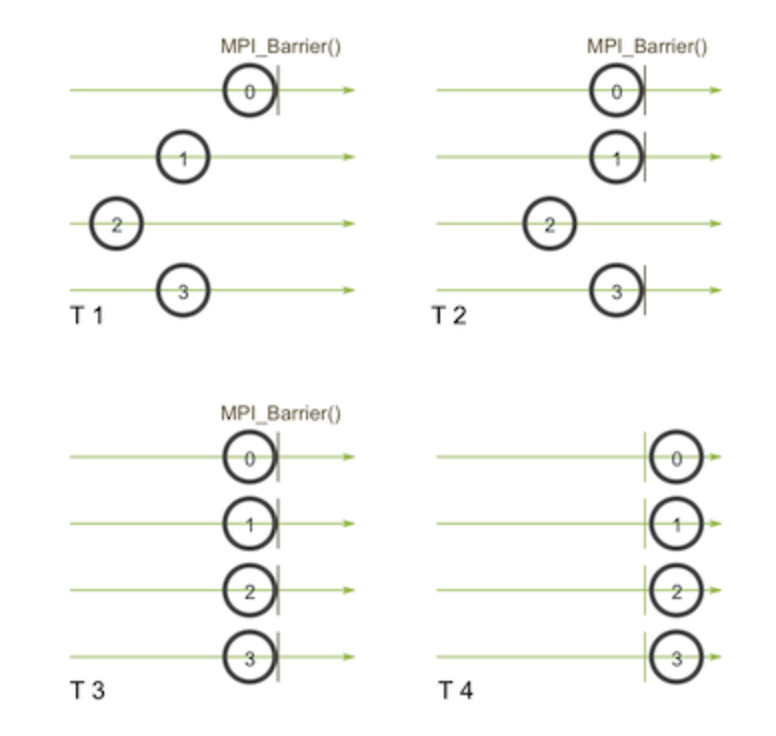
collective communication: 集体通信,通过在进程间引入了同步点的概念达到进程间的同步更新。
附录
Coursera ML笔记 - 逻辑回归(Logistic Regression)
逻辑回归:使用SGD(Stochastic Gradient Descent)进行大规模机器学习
LR模型的特征归一化和离散化
MPI 广播以及集体通信