OLAP(联机分析处理)只是一个概念,背后是一个数据系统,包括数据接入、数据仓库的建设、数据服务(ad hoc查询、可视化、数据挖掘…)。
这里记录下自己的一些思考。
数据仓库
-
数据分层:数据为什么要分层存储?
① 原始数据和应用数据的解耦,使得数据结构更加清晰,也能使得原始业务和应用层的变动不会相互影响。
② 减少重复的数据开发,使得很多对外的数据输出可以复用,也能保证对外数据的一致性。
至于怎么分层,业界比较常见的分层方法是:ods(原始日志层)-> dw(数据仓库层)-> dm(数据集市层)-> app(数据产品层)。个人觉得还是看业务本身的复杂性,根据以往的经验,层数往往和运维的复杂度成正比。所以没有必要为了分层而分层,简单好用才是王道。 -
数据模型:传统DB可能多采用关系建模(ER建模),严格符合3范式。这种约束对于在大数据的场景可能过于严格,所以大数据仓库多采用维度建模。而维度模型最常见的是:
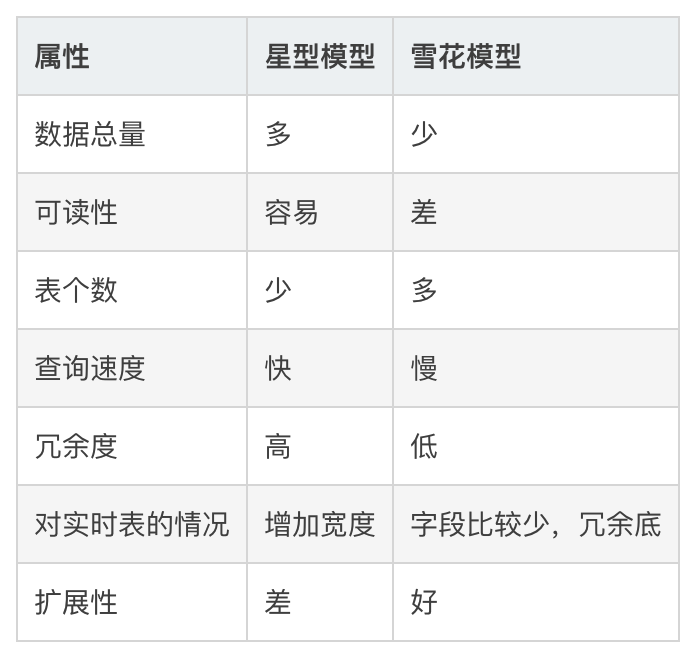
① 星形模型。事实表+一级维度表,可读性好,易维护,聚合查询效率高。
② 雪花模型。事实表+多级维度表。数据冗余少,后期维护较复杂。
对于olap查询系统,个人倾向于星形模型,简单易用,可以省去很多麻烦。贴一下网上找的模型对比:
-
元数据(meta):元数据管理是大数据平台的根基,是数据平台能够很好对外提供服务的基础。其中包括数据schema、业务划分、权限管理、数据血缘等等,甚至延伸到存储信息、计算逻辑…
ETL
除去业务逻辑处理,ETL本质都是join + group by。数据运维、性能优化… ETL大多数问题最后其实都是在处理这两步。join的目的是为了扩展字段成一张宽表(宽表不仅可以简化下游处理逻辑,也能提升处理效率), 但弊端是在回溯历史时带来很大无谓的计算。group by(预聚合)本质上是空间换时间,缺点是存储资源的浪费。
olap框架
早期的olap框架以sql on hadoop为代表,由于sql on hadoop的底层存储在hdfs,就决定了无法真正做到实时响应。所以最近kylin、druid开始大展身手,不过这二位对资源的要求不少,富人才玩得起。
-
sql on hadoop:以hive、impala、presto、Drill、spark为代表。基本思想都是数据存储在hdfs -> 解析sql成查询计划树 -> 翻译查询计划成mr、自定义mpp查询引擎、spark job…。由于spark统一了实时和离线,完美支持了lambda架构,可以说是这类框架的集大成者。
-
kylin:kylin并没有多么复杂的算法支撑和底层实现,它的中心思想很简单:空间换时间,预聚合好数据cube。有时候,简单的往往最有效。但kylin的软肋是实时数据,实际场景应该都是T+1的延迟。
-
druid:在另一篇笔记也有记录,列存+预聚合+倒排索引+MPP内存计算,所以性能还是比较牛的。但是复杂的系统必然会带来运维上的压力。
附录
理解数据仓库中星型模型和雪花模型
[元数据管理解析](https://zhuanlan.zhihu.com/p/36136675)