大数据计算框架日新月异,而每次计算效率的大幅提升,简单总结就一句话:IO优化。不管是存储,还是计算的优化,都是更少的磁盘IO,更多的内存IO。本文结合本人在自身工作中的经验,主要讲一下对大数据计算效率上的一些思考。

技术选型
对大数据查询平台的技术选型,可以从存储和计算两个方面结合自身业务来衡量。
存储
- 扫表vs 索引:建索引可以快速locate需要查询的数据,完全省去了对查询不相关数据的读写IO。但是代价却是漫长的建索引过程和大量额外的存储开销。所以建索引适合经常带filter的数据筛选计算和数据维度基数较多的业务场景。对于一些不带filter的查询和大范围时间内的聚合计算业务场景,建索引就显得多余了
- 列存vs 行存:相比于传统DB的行存,列存能大量减少磁盘IO。比如更高效的数据压缩、查询不需要解压非相关字段、更好的索引策略等。但是在数据更新场景下,列存会带来一些额外的开销。所以对更新频繁的业务场景,选择列存就要慎重了。
计算
- Map reduce vs MPP: 个人觉得二者的边界比较模糊。Map reduce架构扩展性强、可用性高。MPP由于一些不共享约束,使得计算效率相比而言更高(多内存IO,当然对硬件要求也更高)。所以个人觉得,对于一些离线、近实时处理Map reduce架构更可靠(如hive、spark)。而实时计算,多采用MPP架构(比如业界比较流行的计算框架GP、druid、clickhouse等)。
数据预处理
对于数据计算过程最耗IO的两个步骤:JOIN和GROUP BY,可以在数据预处理阶段节省计算过程的IO。
- 预JOIN:大宽表设计,可以省掉计算过程的join IO,这个可能是比较常用的操作,就不多赘述。可能需要考虑的一点是对于经常变动的业务字段,不太适合预JOIN,因为重跑历史数据真的是非常头疼。所以预join的字段最好是不常变动的。
- 数据CUBE:预先group by,简单来说就是空间换时间。apache kylin运用的就是这个方法。但是在海量、高维度的业务场景下,野蛮预建cube的存储代价太大。所以我们提出一种基于组合优化的物化cube智能生成方法:
① 从L(n)出发,计算得到满足覆盖率t的所有n-1规模集合L(n-1), 进一步迭代 L(n-2), L(n-3), …L(n-k), 删选出所有满足最低覆盖率t的组合C;
② 计算每个组合Ci的空间占用Vi 和收益Ri[(r1/r2)*Coverage(pattern)];
③ 转化为0\1背包问题:在满足空间限制V的情况下,选出最大收益R的集合Q。
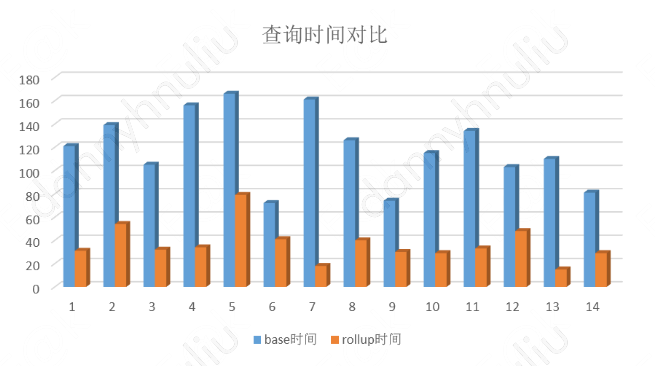
简单来说,就是根据历史查询选出综合考虑查询覆盖和空间占用的最佳组合。下图是查询是否命中cube的时间对比。
查询计划优化
- 分区筛选:根据业务特点可对用户查询添加特定分区筛选条件。举一个我们业务场景的case,当用户查特定广告排期(非分区字段),我们在查询计划加上了筛选该排期下订单(分区字段)的条件,这样省略了大量非必要分区的读写IO。