最近半年花了不少时间在实时olap上,业务场景是全维度实时监控,这里记录下自己的一些思考。
对于大多数大数据底层应用,公司都有很成熟的支持中间件。比如实时消息队列(TDBANK)、KV存储(CKV)、sql on hadoop(tdw)等等。可是实时olap这个场景,基本上都是各个业务自己小规模的玩玩。之前一直想吐槽数据平台不作为,现在自己摸索了这么久才终于明白,实时olap场景的投入产出比 – 真的有点低。
大数据场景下的实时olap,说简单点就是极致的内存计算,极小的磁盘、网络IO。把那么多的数据全堆到内存,听起来都觉得内存和CPU在燃烧。但是实时查询的实际需求又没那么强烈。像弱olap实时查询场景:比如淘宝实时交易额、实时在线人数,其实都可以通过kv系统解决,没必要把所有数据都放内存。而全维度olap场景,sql on hadoop(spark、kylin、impala)可以很好的做到分钟级响应(秒级真有那么重要?)。
话虽如此,但总有些绕不过去的硬需求需要真正意义上的实时olap。
OVERVIEW
-
大数据场景下的olap,区别于大多数sql on hadoop解决方案(hive,spark,impala…),实时oalp(click house,druid,pinot,Vertica…)可以真正意义上做到秒级响应。这主要是因为:
① 定制化的数据存储、压缩、索引,可以极大的减少磁盘IO,增加内存计算。
② 类MPP架构,节点间极少的数据交换,网络IO最小化。 -
当然,这也会带来一些限制:
① 特定的存储使得数据更新变得麻烦,所以很难做到数据的更新和细化删除。
② 不支持节点间数据交换的复杂的计算,比如大表间的join、UV计算(一般是近似计算)。
最近半年在技术选型的时候稍微了解了下业绩的不少开源方案(click house,druid,pinot),这里记录下click house和druid在各个环节的异同。
架构
-
druid: druid的架构从某种程度来说更分布式,更’MPP’。不同的NODE负责不同的工作,且node都采用master-slave架构。所以druid在大集群下的HA表现更好,当然运维部署也会更复杂点。
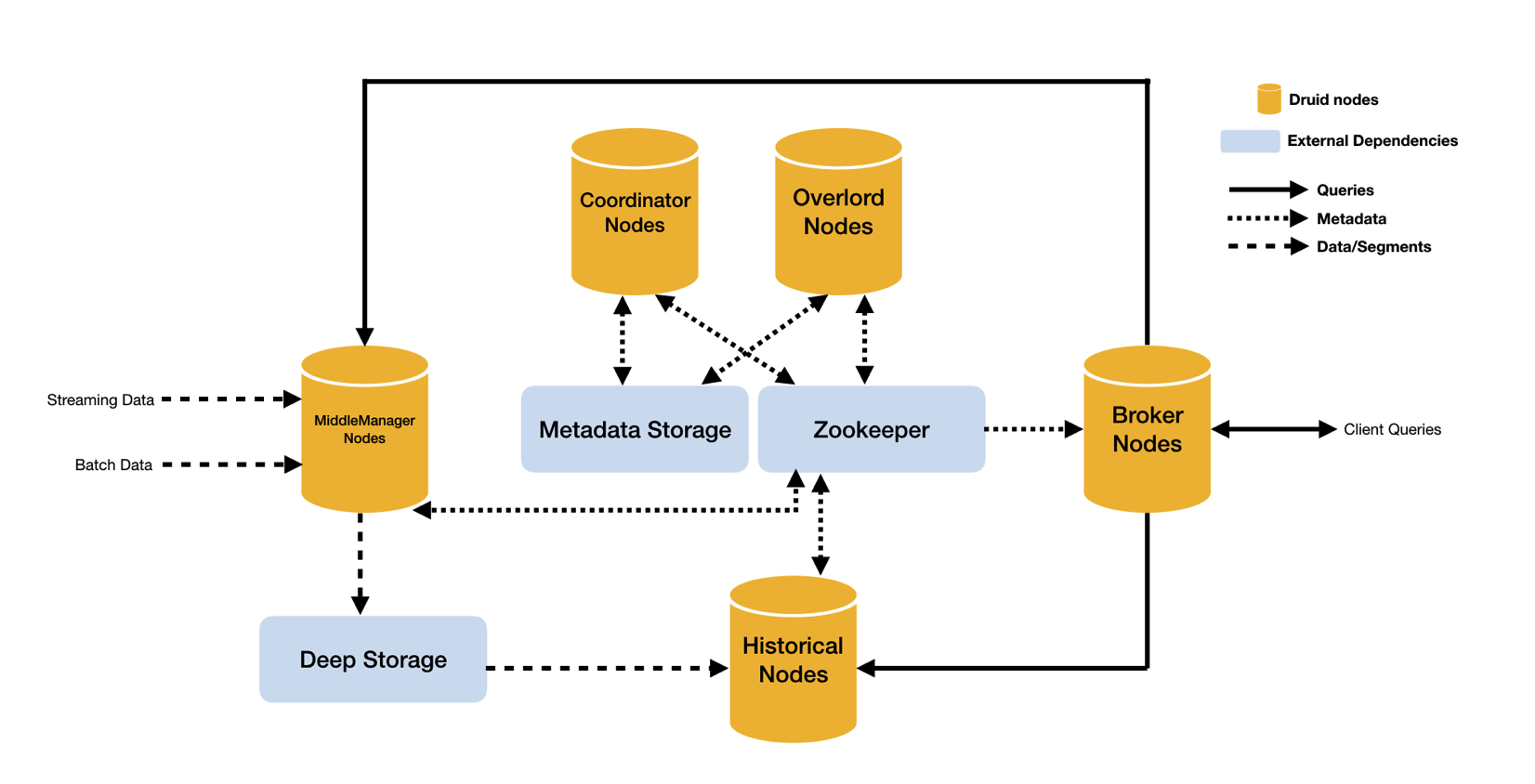
-
click house:ck从某种意义上是可扩展单机DB,专注于单机上的性能压榨,然后在meta记录集群其他节点信息。这样在运维部署相对简单,但应用层也需要做更多分布式的工作,比如入库自己需要做负载均衡。
数据入库
- druid:druid的数据入库相对ck来说有点重,不管是对数据约束还是服务运维。druid支持离线和在线两种入库方式,离线可以和hadoop无缝结合,实时则有专门的realtime node负责数据接入。
- click house:ck则相对简单,数据入库和传统DB类似,比如jdbc连接。但是因为简单,所以应用层需要充分考虑集群的负载。
数据存储
毫无意外,这类db都会采用列存的存储格式。因为列存可以更好的压缩数据,而且在查询时也能节省非必要的解压IO。为了在查询时快速定位数据,ch和druid都对数据作了索引。不过在数据压缩、数据索引、数据备份方面,二者有些小的差别。
-
druid:druid的存储文件格式叫segment。包含timestamp、维度(Dimensions)、指标(Metrics)三部分。segment文件采用LZ4压缩,另外还会维护一个string->int的隐射表,避免了文件中有重复的string字符串。这样做是因为int的压缩效率比string几乎多一个量级。在索引方面,druid会建个bit map做倒排,这对某些filter场景可以减少很多IO。在数据备份方面,druid有一个高效的balance策略把每个segment存储到不同节点。而且有master记录、监控每个segment的状态。
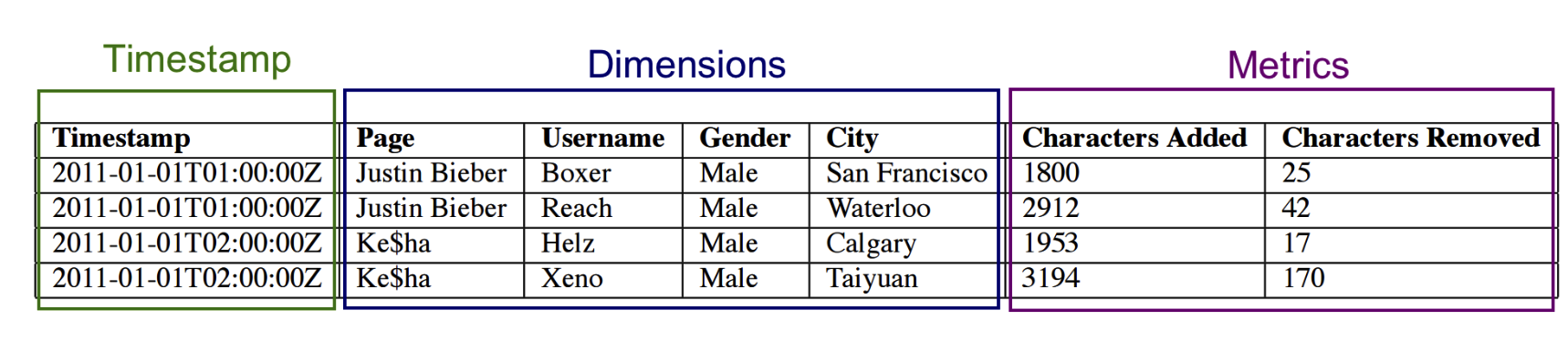

-
click house:ck按分区存储数据,定时对分区进行merge。默认用ZSTD压缩。索引只采用了比较简单的主键稀疏索引。稀疏索引虽然更容易做数据压缩,却不能很好的减少数据读取。所以ck更多时候是做全表扫描,但是由于对主键排序和借助SIMD,ck的读取效率其实非常高。数据备份ck做的比较静态,每个server会记录哪台server是自己的备份。
结论
这里我贴出大牛的对比。简单来说,在数据和集群规模不大的情况下,ck是一个更好的选择。
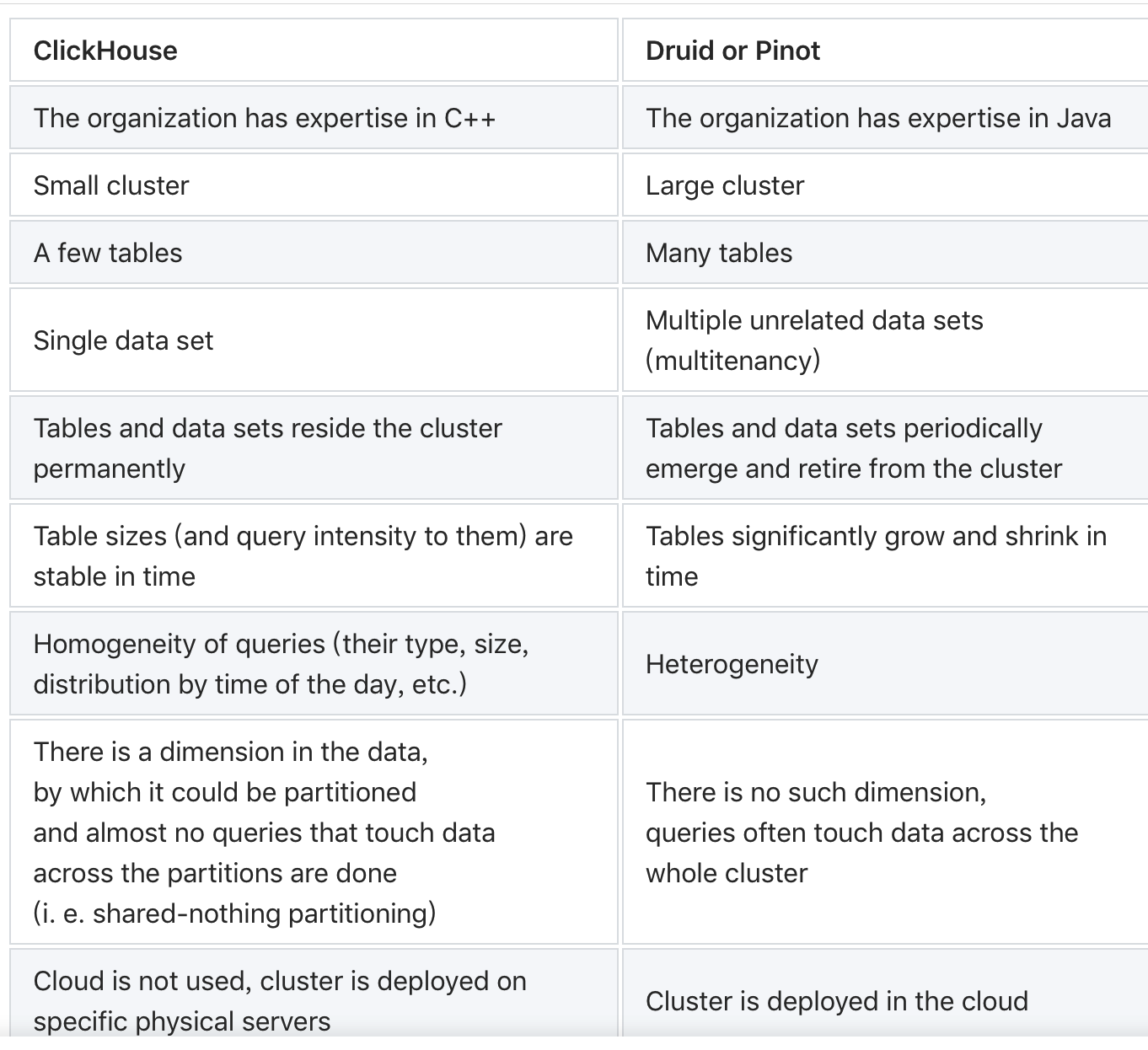
附录
Comparison of the Open Source OLAP Systems for Big Data: ClickHouse, Druid and Pinot