先说观点,spark和flink都是目前能够一站式解决lambda架构的计算框架。因为spark出来的早,现在在活跃度、成熟度方面比flink强。flink发展相对较晚,相比spark各个细节做了很多优化。个人觉得二者是同一个世代计算框架的不同实现,细节方面会相互学习、增强。但要说谁能干掉谁,恐怕都没有这能力。 这里从几个方面比较下二者的区别。
内存管理
-
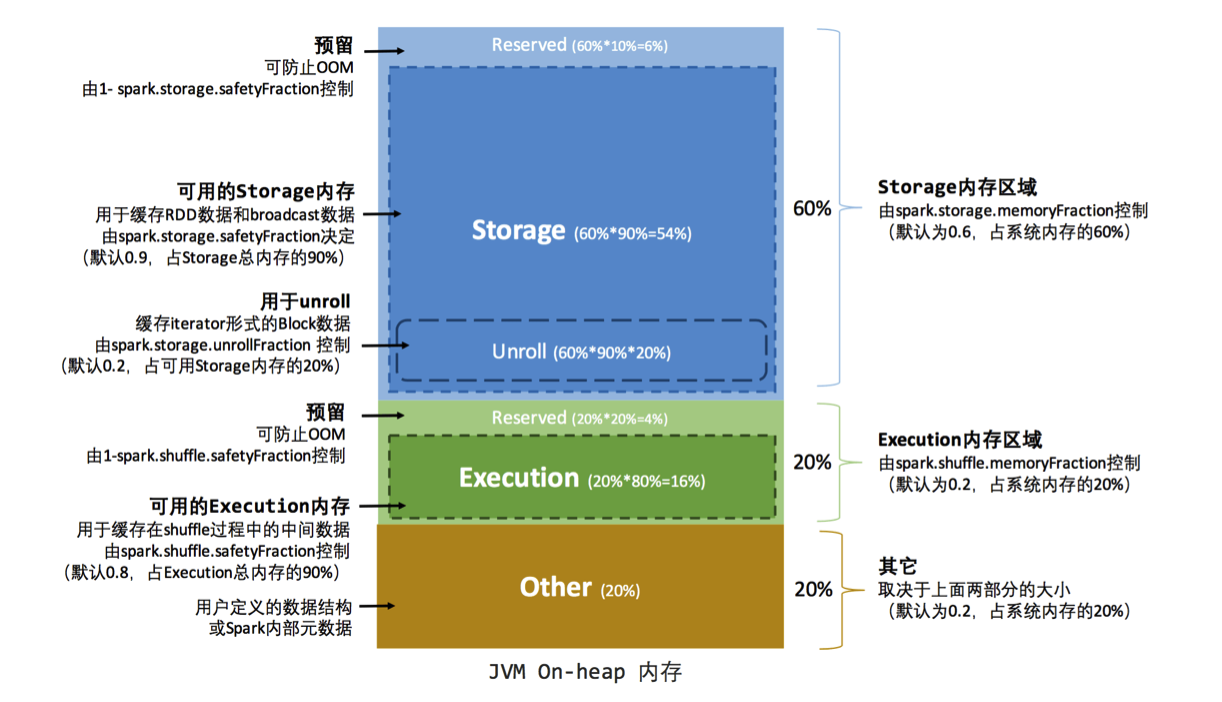
SPARK. executor内存管理算是spark的一个软肋。spark并不会直接操操控jvm上堆内内存,只是进行逻辑上的”规划式”的管理。 当jvm起来的时候,executor会维护Storage、Execution的堆内堆外四个内存map, 分别记录各个块在堆内堆外的内存状态。虽然会有一些防止oom的buffer机制,但这种内存记录器不可能完全准确(比如被spark标记释放的对象可能没有被JVM回收),所以spark不能完全避免OOM。

-
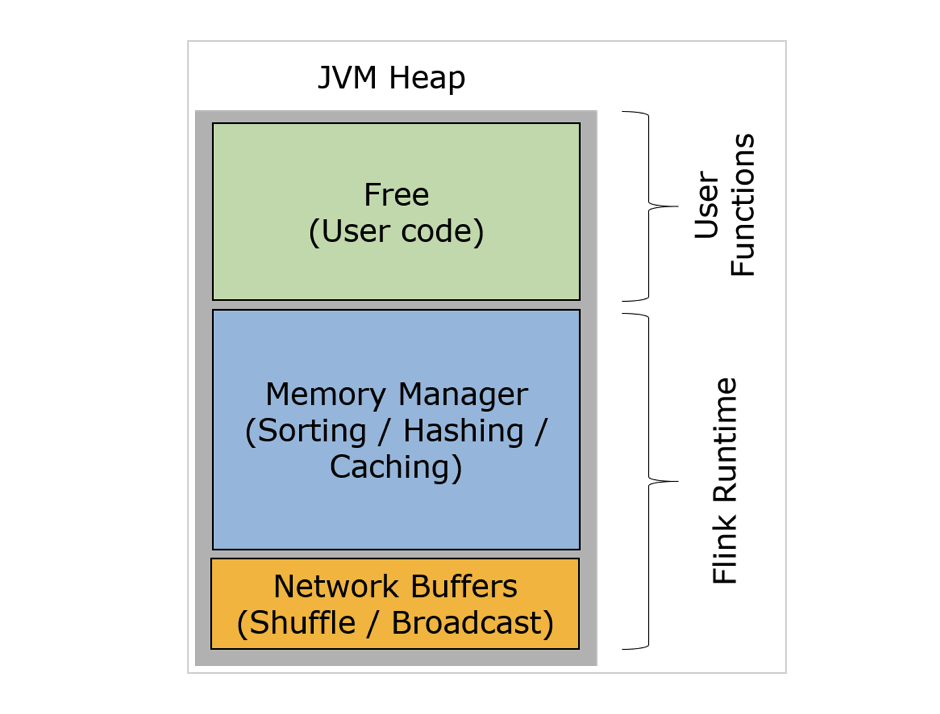
FLINK. 相比spark,flink在内存管理更用心。
① 采用积极的内存管理策略:用专门的内存池负责每个数据片的分配和管理。
② 定制化的数据片操作:高效的二进制操作、量身定制的序列化框架。
抽象
-
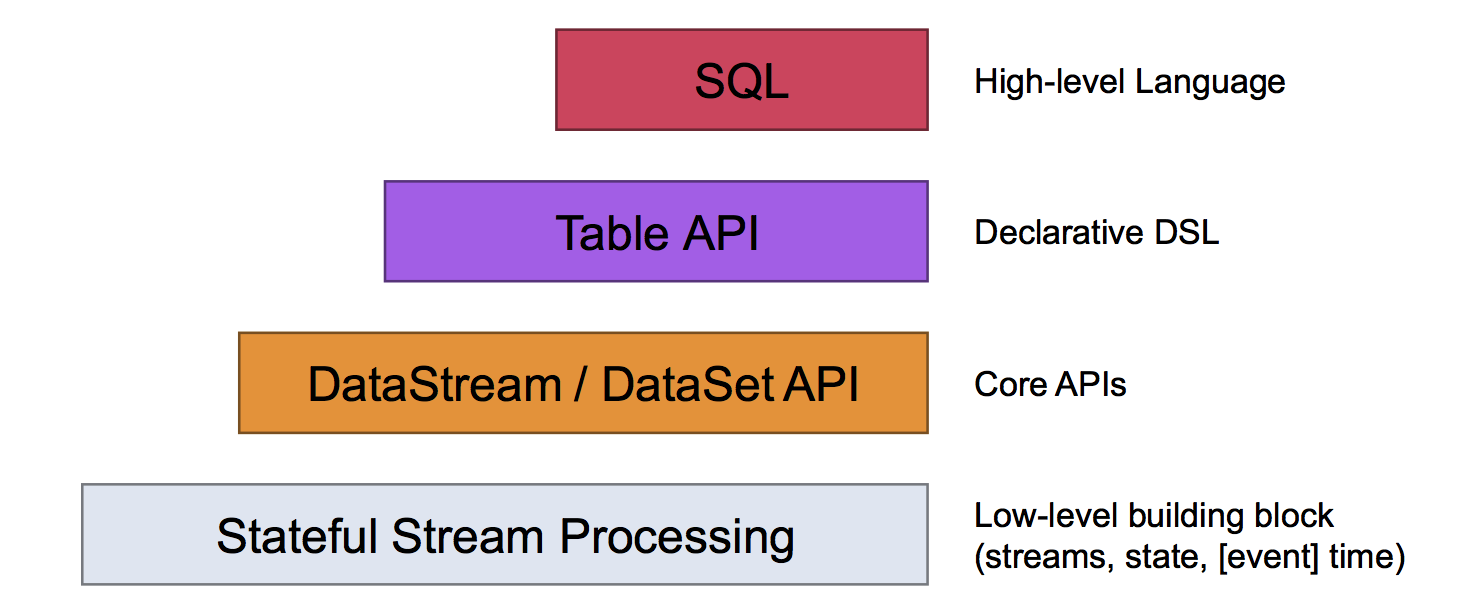
数据模型. 对于底层数据抽象,rdd(Resilient Distributed Datasets)是spark的灵魂。rdd其实是一种分布式的内存抽象,负责处理内存、磁盘数据的分布式存储、和HA(checkpoints)等。spark在rdd上封装出dataset,不管是batch还是streaming都直接通过dataset操控数据。而flink的底层数据抽象成一种有状态流(stateful stream), 然后分别封装成DataStream和Dataset供streaming和batch任务操作数据。在业界普遍无缝结合batch、streaming任务的趋势下,spark的做法显然更合理点。但是flink考虑到了实时计算的上下文状态的重要性,这点更胜一筹。
-
编程模型. 对于数据处理流,spark和flink本质上是一样的。虽然叫法不一样(spark叫job、stage,flink叫transformation、operator),但其实都是map->shuffle->reduce的dag(有向无环图)。
实时计算
在实时计算(streaming)的支持上,flink做的更出色一点。
-
窗口. spark对窗口的支持比较弱,只能根据time interval起batch任务。flink对窗口的支持很强大,既能按时间驱动(比如:每30秒),也能按数据驱动(比如:每100个元素)。而且窗口的类型包括滚动窗口(没有重叠), 滑动窗口(有重叠),以及会话窗口 (由不活动的间隙所打断)。
-
状态. spark streaming不记录数据状态,所以对于一些上下文相关的计算,spark需要借助外部的存储来保存上下文状态。而flink提供了State Backends对历史数据进行保存,比如存在内存(MemoryStateBackend)、文件(FsStateBackend)、外部DB(RocksDBStateBackend),这样会使得一些上下文相关的计算逻辑更易实现。
应用层
应用层因为spark发展的时间比较久,社区也更活跃点,所以在sql、机器学习的支持都已经做的比较成熟了。
-
SQL. 对flink而言,sql层统一了batch和streaming的编程模型。但是由于支持比较晚,各方面还不是很成熟。二者还有一点不同的是,spark的的底层sql解析器是Catalyst,而flink是Calcite。当然,这个差别并没有什么大的意义。
-
ML:同上,相比spark,flink还有很长的路要走。但是相比spark,flink有个天生的优势。spark由于rdd的不可变性,且不支持状态存储,所以在机器学习的迭代过程中显得力不从心。而flink由于支持状态持久化,所以在算法迭代计算过程中会更方便。